【選擇題】
【A】01.提升計算機效率的方法中,有一種叫做管道化處理(pipelining),可以用來改善中央處理單元(central processing
unit, CPU)的效率,其改善效率的方式為何? (A)增加單位時間的指令完成個數 (B)增加中央處理單元中每個元件的運作速度 (C)減少每一個指令執行所需時間 (D)減少危障(Hazard)的產生。[109地方四等資處]
管道化處理(pipelining)技術,可增進單位時間內執行指令的數量。
【A】02.有關直接對映(direct mapped)快取記憶體(cache memory)的定義,下列敘述何者正確? (A)每一個主記憶體(main memory)位址只對映到快取記憶體中的一個位址 (B)存取時只能直接使用實體位址(physical address) (C)快取記憶體中的一個位址僅可存放一個主記憶體位址中的資料 (D)存取時只能直接使用虛擬位址(virtual address)。[109地方四等資處]
直接對映快取記憶體:高速記憶體組織方式,只需做一個位址比較運算,即可找出資料的儲存位址;因主記憶體資料的任一區段在快取記憶體內有一對一位址的對映,故能快速查尋。
【C】03."ADD r1, r2, #2"是ARM微控器裡提供的加法指令之一,會將r2加上2。針對這個指令的敘述下列何者錯誤? (A)該指令使用到暫存器定址模式 (B)該指令使用到立即定址模式 (C)該指令使用到直接定址模式 (D)該指令屬於三位址指令。[109地方四等電子]
指令:將暫存器r2加上2,結果存放在暫存器r1。
直接定址模式:透過記憶體位置直接存取資料,本題未用到。
【C】04.下列何者並非快閃記憶體(flash memory)的優點? (A)相對於同容量的硬碟,擁有較快的讀取速度 (B)相對於同容量的硬碟,比較省電 (C)讀取的速度和寫入的速度同樣的快速 (D)相對於同容量的硬碟,比較耐震。[109身心四等]
讀取速度比較快速
【C】05.關於累加器(Accumulator)的主要功能,下列敘述何者正確? (A)統存放目前執行的指令 (B)記錄堆疊最頂端位址 (C)存放運算過程及運算結果的資料 (D)記錄資料存放在記憶體的位址。[109身心四等]
累加器是一種暫存器,用來儲存ALU的運算結果。
【B】06.假設目前系統中有三個程序(process),其各自所需的執行時間如下表所示。若CPU採用「最短工作先處理(shortest job first)」的方式挑選要執行的程序,且在執行期間沒有其他程序要處理,則這3個程序的平均等待時間為多少毫秒? (A)3 (B)4 (C)5
(D)6。[109身心四等]
|
程序 |
所需時間(毫秒) |
等待時間 |
平均等待時間 |
|
P1 |
9 |
9 |
(3 + 9) ÷ 3 = 4 |
|
P2 |
6 |
6 |
|
|
P3 |
3 |
0 |
【D】07.某處理器具有32-bit定址空間(addressing space),且具有一64KByte的快取記憶體(cache)。此快取記憶體每個cache block為16Byte,以4-way set associative的方式儲存。請問每個cache block的address tag寬度為何? (A)8bits (B)10bits
(C)17bits (D)18bits。[109身心四等]
總位址32bit = tag + set +
word
cache block數 = (64 * 210
* 8) ÷ (16 * 8) = 4 * 210個
set = (4 * 210)
÷ 4 = 210 → 10bits
word = 16 = 24
→ 4bits
tag = 32 - 10 - 4 = 18bits
【D】08.處理器的管道化處理技術(pipelining)可提升運作效率,但是在有危障(hazards)發生時則會降低它所帶來的好處。下列何者不是管道化處理的危障? (A)結構危障(structural hazard) (B)數據危障(data hazard) (C)控制危障(control hazard) (D)計算危障(computation hazard)。[109普考資處]
管道化處理的危障有:結構危障、數據(資料)危障、控制危障。
【D】09.許多計算機中有三層快取記憶體(Cache Memories),分別為L1、L2與L3快取記憶體。下列敘述何者錯誤? (A)存取速度L1>L2>L3 (B)容量L3>L2>L1 (C)多層級快取記憶體設計可以減少整體的錯失懲罰(Miss Penalty) (D)快取記憶體主要功能是彌合中央處理器與硬碟間存取速度的差距。[109普考資處]
快取記憶體主要功能是彌合中央處理器與主記憶體DRAM間存取速度的差距。
【C】10.16個位元形成的位址空間(Address
Space)範圍為何?
(A)0 ~ 4095 (B)1 ~ 4096 (C)0 ~ 65535 (D)1 ~ 65536。[109普考資處]
位址空間範圍:0 ~ 216 -
1 = 0 ~ 65535
【B】11.3-to-8解碼器(Decoder)設計中,高位元到低位元的輸入若為011,下列何者為高位元到低位元的輸出?
(A)00000100 (B)00001000 (C)00010000 (D)00100000。[109普考資處]
|
X |
Y |
Z |
F0 |
F1 |
F2 |
F3 |
F4 |
F5 |
F6 |
F7 |
|
|
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
F0 = X'Y'Z' |
|
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
F1 = X'Y'Z |
|
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
F2 = X'YZ' |
|
0 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
F3 = X'YZ |
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
F4 = XY'Z' |
|
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
F5 = XY'Z |
|
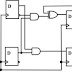
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
F6 = XYZ' |
|
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
F7 = XYZ |
輸入:高位元X 到 低位元Z → 011
輸出:高位元F7 到 低位元F1 → 00001000
【D】12.我們會使用Pipeline來加速程式的執行速度,但執行過程可能會遭遇Data Hazard,下列何者為非常見之Data Hazard? (A)WAW (B)WAR (C)RAW (D)RAR。[109普考電子]
Data Hazard:1.RAW(先寫後讀, Read after Write)。2.WAR(先讀後寫, Write after Read)。3.WAW(寫後寫, Write after Write)。
【B】13.下列關於快取記憶體的敘述,何者正確? (A)目前並無方法可以減少快取記憶體compulsory miss的發生 (B)完全關聯式(fully associative)的快取記憶體可以做到不會有conflict miss的發生 (C)將資料以直接對映(direct-mapped)的方式儲存於快取記憶體中,可以有效降低存取失誤率(miss rate) (D)Capacity miss的發生是因為快取記憶體的容量不夠所造成,所以快取記憶體的容量應該越大越好。[109普考電子]
compulsory miss(強迫性失誤):一開始存取空的快取記憶體時造成的失誤,增加區塊大小可改善,但過大會增加conflict miss。
capacity miss(空間性失誤):快取記憶體的空間無法容納所有需要存取的區塊,增加快記憶體大小可改善。
conflict miss(衝突性失誤):因取代策略造成區塊被取代,並再度對此區塊進行存取時造成的失誤,增加快記憶體大小可改善,使用fully associative可避免所有conflict miss。
【B】14.下列何者對CPU執行程式的效能影響最小? (A)主記憶體的存取速度 (B)CPU內部旗標的位元數 (C)資料滙流排的位元數 (D)CPU內部時序的頻率。[109普考電子]
旗標暫存器(flag register)是16bits的暫存器,但只有9bits被使用。值可用來表示某種狀態(如:二數值的比較結果),進而影響程式執行流程。
【B】15.有一個管道化(Pipelining)處理器,執行一個指令時需要5個步驟:從記憶體中擷取指令、指令解碼並讀取暫存器的值、算術邏輯單元運作、存取記憶體中的資料與將結果寫回暫存器,而每個步驟所需之執行時間分別為200ps、100ps、200ps、200ps與100ps,此處理器的工作時脈最接近下列何者? (A)1GHz (B)5GHz
(C)10GHz (D)50GHz。[109關務四等]
使用最長時間:200ps,ps = 10-12,GHz = 109
1 ÷ (200 * 10-12)
= 1012 ÷ 200 = 1000 * 109 ÷ 200 = 5 * 109
= 5GHz
【D】16.將運算元的位址直接編碼在指令中的是那一種定址模式? (A)暫存器定址(register addressing) (B)立即定址(immediate addressing) (C)位移定址(displacement addressing) (D)直接定址(direct addressing)。[109鐵路員級]
直接定址:指令的運算元位址,採用直接位址來定址;運算元內容儲存在運算元位址。
【B】17.處理器在執行程式時,目前正在或即將被執行的指令的位址,儲存在下列那一元件? (A)加法器(adder) (B)程式計數器(program
counter) (C)多工器(multiplexer)
(D)一般暫存器(general purpose register)。[110地方四等資處]
程式計數器:指出下一個要執行指令的記憶體位址。
【A】18.發掘程式中指令階層平行性(instruction-level parallelism)有助於提升程式執行效能,其可由硬體或是軟體的機制來達成。下列何者需要依賴純軟體的方式,以發掘指令階層平行性進而提升程式效能? (A)很長指令字(Very Long Instruction Word, VLIW)架構 (B)超純量(superscalar)架構 (C)動態管道排程(dynamic
pipeline scheduling) (D)亂序執行(out-of-order
execution)。[110地方四等資處]
很長指令字架構,將多個指令連在一起,提升程式執行效能。
【C】19.程式的執行時間中有一部分稱為中央處理器執行時間(CPU execution
time)。下列何者與中央處理器執行時間無關? (A)程式中的指令數(Instruction Count) (B)每個指令時脈數(Clock Cycles Per Instruction)
(C)快取錯失率(Cache Miss Rate) (D)時脈速率(Clock Rate)。[110地方四等資處]
CPU
Clock Cycles = CPI × Instruction Count
CPU
Time = CPU Clock Cycles × Clock Cycle Time = CPU Clock Cycles ÷ Clock Rate
【D】20.下列四個暫存器中,那一個用來存放CPU下一個所要執行之指令在主記憶體中的位址? (A)狀態暫存器(Status Register) (B)指令暫存器(Instruction Register) (C)累加器(Accumulator) (D)程式計數器(Program
Counter)。[110身心五等]
程式計數器:指出下一個要執行指令的記憶體位址。
【A】21.大雄購買了一顆CPU,包裝上標示著4.8GHz,試問4.8GHz所代表的意思是下列何者?
(A)CPU的時鐘脈衝為每秒4.8Giga次 (B)CPU每秒可以存取4.8Giga筆資料 (C)CPU每秒可以執行4.8Giga個程式 (D)CPU內部的記憶體大小為4.8Giga個位元組。[110身心五等]
GHz(Giga
Hertz):頻率單位,每秒十億次震盪(10^9)
【B】22.電腦運行中,可能會有中斷(interrupt)訊號發生,下列敘述何者錯誤? (A)CPU的動作是先將目前機械碼指令處理完,再處理中斷訊號,而非立即處理此中斷訊號 (B)CPU在處理中斷訊號時,一定要先關閉中斷機制,等到此中斷處理完成,才能再開放中斷機制,否則期間又有中斷發生時,系統必然會出錯 (C)中斷訊號可能來自硬體電路,也可能來自軟體程式 (D)有些中斷訊號的發生時間可以預期。[110身心五等]
中斷的過程:
1.CPU將當前的狀態(PCB)做暫存
2.CPU根據中斷向量找尋到作業系統(OS)中所對應的中斷程式ISR(Interrupt Service Routine)
3.CPU執行OS的中斷程式
4.執行完後,OS會讓行程回復之前狀態並繼續執行
並沒有要先關閉中斷機制
【A】23.假設計算機A與B使用相同的指令集架構(Instruction Set Architecture),且A與B的時脈週期分別為250ps與500ps。在A與B上執行某一個高階程式語言所編譯出的執行檔時,計算機A與B之每一指令的平均時脈數(Clock
Cycles per Instruction, CPI)分別為2與1.5。對該程式而言,那個計算機較快,以及快幾倍? (A)計算機A比計算機B快1.5倍 (B)計算機A比計算機B快2倍 (C)計算機B比計算機A快1.5倍 (D)計算機B比計算機A快2倍。[110身心四等]
假設程式中的指令數目為N
A的CPU時間 =
2N * 250 = 500N
B的CPU時間 =
1.5N * 500 = 750N
A的執行速度較快,750N ÷ 500N = 1.5倍
【C】24.可以將資料與指令綁定於記憶體中的位址的時機共有三個時期,其中不包含下列何者? (A)編譯時期(compile time) (B)載入時期(load
time) (C)除錯時期(debug time)
(D)執行時期(execution time)。[110身心四等]
位址定位(Address Binding)有:編譯時期、載入時期、執行時期等三個時期。
【D】25.現在幾乎所有的桌上型計算機與伺服器內的處理器都是多核心的,假設有一個4核心處理器(Multiple core
Processor),每個核心的時脈速度(Clock Rate)皆為1GHz,且每個核心一個時脈週期(Clock Cycle)可以執行2個指令,則理想情況下該處理器一秒內最多可以執行多少指令? (A)109 (B)2
* 109 (C)4 * 109 (D)8 * 109。[110身心四等]
每秒可執行指令數 = 4 * 2 * 109 = 8 * 109
【B】26.假設CPU的工作頻率為4GHz,平均執行一個指令約需花費2個時脈週期(clock cycle),則該CPU平均執行一個指令約需花用多少時間? (A)0.25ns (B)0.5ns
(C)1ns (D)2ns。[110初考資處]
4GHz = 4 * 109
平均時間 = 2 ÷ 4 * 109 =
0.5 * 109 = 0.5ns
【A】27.計算機負責CPU與其他低速周邊裝置溝通的是下列何者? (A)南橋晶片 (B)北橋晶片 (C)BIOS (D)PCI Express。[110初考資處]
南橋晶片:負責低速裝置的溝通,如:PCI、IDE、USB、SATA、I/O連接埠。
北橋晶片:負責高速裝置的溝通,如:CPU、主記憶體、顯示卡裝置。
【B】28.計算機CPU中的程式計數器(program counter),主要任務為何? (A)將指令的數據運算元,從記憶體中被擷取,並置入CPU的暫存器中 (B)控制單元透過它來判斷指令位置,從記憶體中擷取程式中下一道指令 (C)解碼指令成ALU單元能夠了解的語言形式 (D)在程式指令中,進行已經執行的指令計數工作。[110國安五等]
程式計數器:指出下一個要執行指令的記憶體位址。
【B】29.有關CPU的中斷處理(interrupt handling),下列何種事件一般不會處置? (A)I/O請求 (B)正常的暫存器讀寫流程 (C)算數錯誤或溢位 (D)硬體誤動作。[110國安五等]
中斷要求的主要應用有:1.協調I/O動作與處理資料速率緩慢的I/O資料轉移資料。2.偵測軟體程式執行時,可能產生的意外情況。3.偵測硬體電路的意外狀況。4.提供使用者存取系統資源的管道。5.提供危機性事件的處理。6.提醒CPU定時的處理例行性程式。
【A】30.假設一台電腦的CPU具有500MHz之規格,若此電腦之Move指令需要5個時脈週期(clock cycle),則執行此一指令大約需要多少時間? (A)10ns (B)2.5ns (C)1ns
(D)25ns。[110國安五等資處]
5×1/(500×106) = 1×10-8 = 10×10-9 = 10ns
【C】31.不同的計算機系列使用不同的指令集(Instruction Set),目前指令集設計有複雜指令集計算機(Complex Instruction Set
Computer, CISC)與精簡指令集計算機(Reduced Instruction Set Computer, RISC)兩個主要趨勢。針對兩者的比較,一般而言,下列敘述何者正確? (A)RISC的單一指令所能完成的工作較多 (B)RISC的計算機硬體設計會較複雜 (C)完成相同的工作CISC所需使用的指令數量較少 (D)CISC的工作時脈較容易被提高。[110普考資處]
CISC:使用功能較多、較強的指令,電路設計複雜,成本高,容易處理複雜的指令,編譯器的撰寫較簡單。
RISC:使用少量、常用、功能簡單的基本指令,來完成複雜的指令,執行速度快,電路設計容易。
【A】32.某個中央處理單元(Central Processing Unit, CPU)的時脈速度(Clock Rate)為1GHz,假設一個時脈週期(Clock Cycle)可以執行一個指令,理想情況下該處理器一秒內可以執行多少指令? (A)109 (B)1030
(C)29 (D)230。[110普考資處]
1GHz(Giga Hertz):每秒十億次震盪(109)
【C】33.某處理器執行某程式時,平均每個指令耗時5ns,如果以百萬指令每秒(million instructions
per second, MIPS)呈現該處理器對該程式的速度,則下列何者正確? (A)2MIPS (B)20MIPS (C)200MIPS
(D)2000MIPS。[110普考資處]
CPU執行速度 = 1/5ns = 1/(5×10-9) = 0.2×109 = 200×106 =
200MIPS
【D】34.設計計數器(Counter)時,若某一級正反器(Flip-flop)的輸出接到其他任一級正反器的時脈(Clock)輸入,則這樣的計數器應稱之為 (A)飽和(Saturating)計數器 (B)循環(Circular)計數器 (C)同步(Synchronous)計數器 (D)漣波(Ripple)計數器。[110普考資處]
漣波計數器:又稱異步計數器(Asynchronous Counter),由一連串的JK正反器所構成。每一級的輸出接到下一級的時鐘(CK)輸入端,時鐘信號加到第一級的CK輸入。

clock→上方D型 1ns→AND gate 2ns→XOR gate 4ns→D型輸入 3ns
最短時脈週期=1+2+4+3=10ns
【A】36.定址模式(addressing modes)是利用特定的規則解譯指令,並決定指令所包含之運算元的內容。下列何種定址模式,可最快取得運算元之值? (A)立即定址方法(immediate addressing)
(B)虛擬直接定址法(pseudodirect
addressing) (C)基底定址法(base addressing) (D)PC相對定址法(program
counter-relative addressing)。[110關務四等]
定址法分為立即定址、直接定址與間接定址。
立即定址法:使用一個立即運算元(immediate operand),而不須記憶體的存取動作。如:A = 123。
【D】37.常見用來敘述一個處理器的時脈速率規格為GHz(Gigahertz),如:某個特定處理器最高運作時脈為1GHz,假設一個時脈週期可以執行一個指令,則此1GHz所代表的意義為何? (A)一個小時最高可處理106個指令 (B)一分鐘最高可處理106個指令 (C)一分鐘最高可處理109個指令 (D)一秒鐘最高可處理109個指令。[110關務四等]
1KHz = 每秒處理103個指令。1MHz = 每秒處理106個指令。1GHz = 每秒處理109個指令。
1THz = 每秒處理1012個指令。
【A】38.某個中央處理單元(Central Processing Unit, CPU)的時脈週期(Clock Period)是50皮秒(Picoseconds, ps),則其時脈速度為多少GHz? (A)20GHz (B)50GHz
(C)200GHz (D)500GHz。[110關務四等]
時脈頻率= 1 ÷ 時脈週期 = 1 ÷ 50ps = 20GHz
【C】39.一部計算機中的各主要功能單元的運作時間如下:記憶體存取需300ps、算術邏輯單元運作需100ps、以及暫存器讀寫需250ps。在管道化處理(Pipelining)機制中,執行指令時需要有5個步驟:從記憶體中擷取指令、讀取暫存器的值(同時解碼指令)、算術邏輯單元運作(可能是計算位址)、存取記憶體中的資料、將結果寫回暫存器,此管道化實作計算機的一個時脈週期,應該設定成多少最合適? (A)100ps (B)250ps
(C)300ps (D)1200ps。[110關務四等]
管道化是假設程式執行時,有一連串的指令要被執行(垂直座標是指令集i,水平座標是時間t)。絕大多數的CPU都是利用時脈驅動。
【D】40.相較於複雜指令集電腦CISC(Complex Instruction Set
Computer)CPU而言,精簡指令集電腦RISC(Reduced Instruction Set Computer)CPU的特點,不包括下列那一項? (A)RISC CPU指令集中的指令個數較少 (B)RISC CPU的指令格式較少 (C)RISC CPU的硬體較容易做管線(pipelining)設計 (D)高階語言程式編譯出的RISC機器碼(和CISC機器碼相比)較節省記憶體空間。[110鐵路員級]
複雜指令需要由許多的小指令去完成,程式變大,沒有比較節省記憶體空間。
【D】41.有關計算機結構之敘述,下列何者正確? (A)SCSI是一種計算機體系結構,可利用多個指令流對多個數據流進行操作 (B)RISC代表遞迴指令集計算機(recursive instruction
set computer) (C)CISC代表完整指令集計算機(complete instruction set computer),它具有大量指令集 (D)SIMD代表單指令流、多數據流。[111地方四等資處]
(A)SCSI(Small Computer System Interface)是做為周邊零件的數據傳輸,例如:硬碟、CD-ROM等設備而設計的界面。
(B)精簡指令集(Reduced Instruction Set
Computer, RISC):指令長度短,指令數少。
(C)複雜指令集(Complex Instruction Set
Computer, CISC):指令長度長,指令數多。
【C】42.下列那一項不是同時執行多項活動的方法? (A)管線化(pipelining) (B)多程式(multiprogramming) (C)動態記憶體重新整理(DRAM refresh) (D)多處理器(multiple processors)。[111地方四等資處]
(A)管線化:不同指令的不同週期會同時執行。
(B)多程式:多個程式存放到記憶體中,以平行或並行方式處理。
(C)DRAM的元件為電容,需要周期性充電(Refresh),以保存內部資料。
(D)多處理器:同一個主機有多個處理器。
【A】43.各項訂定CPU指令集架構的策略,下列何者屬於CISC(Complex Instruction
Set Computer)處理器的設計方針? (A)透過指令編碼並允許不同指令,可擁有不同的指令長度,以減少程式碼占用的記憶體空間 (B)維持所有指令皆有相同長度的編碼,以便於設計pipeline架構的處理器 (C)僅有指定的load/store指令可讀寫記憶體內容,其他指令皆僅能使用暫存器作為運算元,以便編譯器進行最佳化 (D)配置較多的一般用途暫存器,並透過編譯器進行暫存器配置,以提升運算效能。[111地方四等電子]
精簡指令集(RISC):指令長度短,指令數少。(B)(C)(D)是RISC的特性。
複雜指令集(CISC):指令長度長,指令數多。

【B】45.將原來只有L1快取記憶體的系統,再加上L2快取記憶體的主要目的,不包含下列何者? (A)降低失誤代價(Miss penalty) (B)降低L1失誤率(Miss rate) (C)降低程式執行時間 (D)降低平均每個指令執行所須週期數。[111地方四等電子]
L1快取位於處理器晶片中,執行速度和CPU一樣。L2快取通常是CPU模組的一部分,容量比L1快取稍大,執行速度稍慢。所有快取的作用都是為了降低記憶體的平均存取時間。
【A】46.一般而言,增加管線階級(Pipeline stages)數,可以造成下列何種結果? (A)處理器時脈頻率的提高 (B)記憶體容量的增加 (C)危障(Hazard)發生機會的減少 (D)效能的降低。[111身心四等]
(A)增加管線數,加速指令通過速度,時脈頻率會提高。(B)與記憶體容量無關。(C)增加管線數,危障發生機會可能增加。(D)危障發生機會增加,效能會降低。
【C】47.關於CPU的精簡指令集(RISC)與複雜指令集(CISC)之描述,下列何者錯誤? (A)RISC指令種類較少、CISC指令種類較多 (B)RISC指令格式較無彈性、CISC指令格式較有彈性 (C)RISC指令無明顯最佳化、CISC指令進行最佳化 (D)RISC指令功能較簡單、CISC指令功能較複雜。[111初考資處]
RISC致力於處理器最佳化。CISC著重於降低程式的複雜度。
【C】48.某個中央處理單元(Central Processing Unit, CPU)的外頻為500MHz,其倍頻為2,此中央處理器內部運作的時脈速度(Clock Rate)是多少? (A)250MHz (B)500MHz
(C)1GHz (D)2GHz。[111普考資處]
內頻=外頻×倍頻=500MHz×2=1GHz
【A】49.下列那一種方法無法用來處理管線化(Pipeline)CPU所遭遇到的控制危障(Control Hazard)問題? (A)資料前饋(Data Forwarding) (B)分支預測(Branch Prediction) (C)延遲分支(Delayed Branch) (D)管線暫停(Stall)。[111普考資處]
管線危障(pipeline hazards)可能出現的衝突情況:1.資源衝突,2.指令層的資料衝突,3.傳輸層的資料衝突。
可透過增加功能單位來解決資源衝突。可透過分支預測器來避免控制衝突。
【D】50.傳播延遲(Propagation delay)為二進位輸入訊號改變其值時,從輸入傳遞到輸出轉變的延遲時間。以64位元來說,下列那一種加法器,其傳播延遲時間最長? (A)前瞻進位加法器(Carry-Lookahead Adder)
(B)進位選擇加法器(Carry-Select Adder) (C)進位儲存加法器(Carry-Save Adder) (D)漣波進位加法器(Ripple-Carry Adder)。[111普考資處]
漣波進位加法器(RCA):電路布局簡單,設計方便,但高位運算必須等到低位運算完成,延遲時間會比較長。
【B】51.某中央處理器的執行速度為300MIPS(Million Instructions Per
Second),且其CPI(Cycles Per
Instruction)為2,此處理器的運行時脈為何? (A)300MHz (B)600MHz (C)3GHz
(D)6GHz。[111關務四等]
運行時脈=300×106×2=600×106=600MHz
【C】52.全加器(full adder)能將兩個位元以及進位輸入(carry in)相加。其輸出有和(sum)及進位輸出(carry out)。若這個全加器只能使用Inverter、AND與OR這三種邏輯閘,其中AND與OR邏輯閘的輸入可以不只兩個,則所使用的AND與OR邏輯閘的個數總和至少為多少個? (A)7個 (B)8個 (C)9個 (D)10個。[111關務四等]
【C】53.一個程式的執行時間與其平均每個指令所需執行的時脈週期數(Cycles Per Instruction,
CPI)有關,下列何者最不會影響執行時間? (A)演算法 (B)編譯器 (C)硬碟容量 (D)CPU品牌。[111關務四等]
影響程式執行時間的因素:CPU品牌、編譯器、演算法。
【C】54.在處理器的指令設計中,有些指令會被用在作業系統核心中來實作多工系統共享資源的保護機制,例如互斥鎖(mutex)。下列那一個指令的主要功能是用來實現這個機制? (A)乘累加指令(multiply-accumulate)
(B)關閉中斷的指令(disable interrupt) (C)不可切分的讀取並設定指令(atomic test-and-set)
(D)檢查溢位旗標的指令(check overflow flag)。[111關務四等]
不可切分的讀取並設定指令,可以確保在讀取和設定值的過程中,不會被其他的處理器或線程中斷。
【B】55.CPU在處理下列那一項工作時,不需要做系統呼叫(system call)? (A)CPU執行的程式要新建一個資料檔 (B)CPU執行的程式要讀取使用者空間中的一筆資料 (C)CPU執行的程式要求使用者從鍵盤輸入一筆資料,當作某變數的值 (D)CPU執行的程式要求動態記憶體配置(dynamic memory
allocation)。[111鐵路員級]
系統呼叫:運行在使用者空間的程式向作業系統核心請求需要更高權限運行的服務。系統呼叫提供使用者程式與作業系統之間的介面。
【A】56.關於CISC和RISC的比較,下列何者錯誤? (A)RISC的效能比CISC的佳,因此CISC已經不再使用 (B)RISC的指令雖然比較少,但是執行速度也較快 (C)CISC的電路設計比較複雜,成本也較高 (D)CISC是指CPU内使用較多較複雜的指令。[112地方四等資處]
(A)CISC(複雜指令集)和RISC(精簡指令集)都仍然存在。
【C】57.下列何者不屬於CPU(Central Processing Unit)的構成部分? (A)算術邏輯單元(Arithmetic/Logic Unit) (B)控制單元(Control Unit) (C)主記憶體(Main Memory) (D)暫存器(Register)。[112地方四等電子]
CPU組成單元:CU+ALU+暫存器(Register)+快取記憶體(Cache Memory)。
【C】58.電腦CPU使用重複的機器週期(Machine Cycle)逐行執行程式(Program)中的指令。一個機器週期包含三個步驟的先後順序是 (A)擷取(Fetch)、執行(Execute)、解碼(Decode) (B)解碼、執行、擷取 (C)擷取、解碼、執行 (D)解碼、擷取、執行。[112身心五等]
指令運作周期:擷取、解碼、執行、儲存
【D】59.若在某單程式作業系統(Mono-programming Operation System)執行程式,平均使用CPU的時間是20微秒(Microseconds)、使用I/O設備的時間是60微秒。則該系統CPU空閒的時間百分比是多少? (A)20% (B)45% (C)60%
(D)75%。[112身心五等]
CPU空閒時間百分比=空閒時間÷總CPU時間=60÷(20+60)=75%
【C】60.關於電腦開機過程與作業系統(OS),下列敘述何者錯誤? (A)OS是硬體與應用程式間的介面 (B)OS是硬體與使用者間的介面 (C)電腦開機過程中,須由CPU先載入OS,再執行啟動程式(Bootstrap) (D)電腦開機過程中,須由CPU先執行啟動程式(Bootstrap),再載入OS。[112身心五等]
開機流程:
1.載入BIOS的硬體資訊與進行自我測試,並依據設定取得第一個可開機的裝置。
2.讀取並執行第一個開機裝置內MBR的Boot Loader(即grub, spfdisk等程式)。
3.依據Boot Loader的設定載入Kernel,Kernel會開始偵測硬體與載入驅動程式。
【A】61.一般電腦主機板中負責CPU、RAM與顯示卡等主要高速裝置溝通的晶片為 (A)北橋晶片 (B)南橋晶片 (C)顯示晶片 (D)數位類比轉換器。[112初考資處]
北橋晶片:負責高速裝置的溝通,如:CPU、主記憶體、顯示卡裝置。
南橋晶片:負責低速裝置的溝通,如:PCI、IDE、USB、SATA、I/O連接埠。
【A】62.請問MGz、GHz通常是被用來描述下列那一個電腦元件的規格? (A)CPU運算的速度 (B)網路傳輸速度 (C)列印的解析度 (D)動態硬碟的大小。[112國安五等資處]
(A)MGz、GHz用來描述CPU運算的速度,時脈頻率高,代表電腦執行快,處理效能高。
【B】63.在電腦被關機後還是會消耗少量的電源,這是因為那個元件還在繼續的運作? (A)CPU (B)時脈 (C)硬碟 (D)USB。[112國安五等資處]
(B)電腦關機後,時脈元件仍然會消耗少量的電源,維持時脈的穩定運行,以確保在需要時能夠正確地重新啟動系統。
【D】64.一個4GHz的中央處理器,最快需要多少時間可執行一個指令? (A)25ns
(B)12.5ns (C)1.25ns (D)0.25ns。[112普考資處]
4GHz = 4 * 109
每個指令執行時間 = 1 ÷ 4 * 109 =
0.25 * 109 = 0.25ns
【A】65.下列那一種定址模式其運算元,即為指令中所含的一個常數? (A)立即定址法(immediate addressing)
(B)暫存器定址法(register addressing)
(C)基底或位移定址法(base or displacement
addressing) (D)PC相對定址法(PC-relative addressing)。[112普考資處]
立即定址法之運算元,即為指令中所含的一個常數,可直接執行數學和邏輯運算。
【D】66.提升中央處理單元(Central Processing Unit, CPU)效能的方法中,有一種叫做管道化(Pipelining)的技術。對該技術的敘述,下列何者正確? (A)可以減少每個指令的執行時間 (B)可以降低中央處理單元中線路的大小 (C)允許指令以任意次序執行 (D)指令從擷取至完成所需的時間平均變得更長。[112普考資處]
在執行相同的指令時,非管道化處理器的指令傳輸延遲時間(the instruction
latency)比管道化處理器較短。因為管道化處理器必須在數據路徑(data path)中添加正反器(flip-flops)。
【D】67.有關電腦系統中記憶體的敘述,下列何者錯誤? (A)快取記憶體(Cache Memory)的存取速度比隨機存取記憶體(Random Access Memory)快 (B)快閃記憶體(Flash Memory)可用於電腦基本輸入輸出系統(BIOS)的存放 (C)在隨機存取記憶體(Random Access Memory)中,讀取任一位址資料的所需時間都是一致的 (D)暫存器(Register)透過數值類型的記憶體位址以進行存取。[112普考資處]
暫存器是中央處理器內用來暫存指令、數據和位址的電腦記憶體。暫存器沒有記憶體位址。
【A】68.在設計管線式(pipeline)處理器時,需搭配各式軟硬體的設計機制,以減少管線因data hazard損失的運算效能。下列優化運算效能的技術,何者不能於編譯器(compiler)上實施? (A)Data forwarding
(B)Instruction scheduling (C)Register renaming (D)Software pipelining。[112普考電子]
Data Forwarding(數據前送):CPU在一個時脈週期內,把一個單元的輸出值內容拷貝到另一個單元的輸入值中。
【D】69.在記憶體階層架構裡,下列敘述何者錯誤? (A)主記憶體通常使用隨機存取記憶體(RAM) (B)CPU裡面的暫存器(Registers)存取速度最快 (C)硬碟屬於輔助記憶體 (D)在CPU與主記憶體之間可以使用快閃記憶體(Flash memory)來提昇系統的效能。[112普考電子]
(D)在CPU與主記憶體之間可以使用快取(Cache)來提升系統的效能
【D】70.關於process與thread的敘述,下列何者錯誤? (A)在多核心系統上的平行程式,可以在單一process內部執行多個thread的方式實現 (B)在多核心系統上的平行程式,可以多個process的方式實現 (C)在單一process內部的不同thread之間,可透過global variable交換資料 (D)在不同process的thread之間,可透過global variable交換資料。[112普考電子]
(D)不同的process各有獨立的記憶體空間,沒有共享記憶體,無法透過global variable交換資料。
【C】71.某計算機系統具有32bits位址的記憶體定址空間,並包含一個direct mapped快取記憶體(cache),該快取記憶體每個cache block為8Bytes,且必須儲存17bits的位址做為tag。該快取記憶體的大小為何? (A)8KByte (B)16KByte
(C)32KByte (D)64KByte。[112普考電子]
直接對映主記憶體的格式:標籤 + 區塊框編號 + 相對位址
區塊框編號欄的位元依區塊數量,相對位址欄的位元依block大小
cache block的大小 = 8Bytes = 23Bytes
32 = 17 + 12 + 3
區塊框編碼需12bits,區塊數量為212個
快取容量 = 區塊數量×區塊大小 = 212 × 23Bytes = 25 × 210Bytes = 32KBytes
【C】72.程式執行的流程有時必須根據指令執行的結果而改變,在處理器管線(Pipelining)架構中,這種情形將會引發何種危障(Hazard)? (A)資料危障(Data Hazard) (B)結構危障(Structure Hazard) (C)控制危障(Control Hazard) (D)程式危障(Program Hazard)。[112普考電子]
控制危障發生於需要根據前一指令執行結果來判斷下一個要執行的指令,會造成流水線停滯(Pipeline stall)。
資料危障發生於指令之間的資料相依性。結構危障涉及硬體資源的衝突。程式危障則與特定的程式設計問題相關。
【C】73.傳統的電腦系統架構中,CPU通常到那裡取得指令來執行? (A)程式計數(Program Counter)暫存器 (B)通用暫存器 (C)主記憶體 (D)輔助記憶體。[112普考電子]
(A)程式計數器:指出下一個要執行指令的記憶體位址。
(B)通用暫存器:暫存一般運算資料及位址資料。
(D)輔助記憶體:存放暫時用不到的程式和資料。
【D】74.下列何者不是RISC處理器的主要特徵? (A)較少的指令集與定址模式 (B)記憶體存取只限於載入及儲存指令 (C)所有的運算都在CPU的暫存器間處理 (D)不同長度的指令格式。[112關務四等]
(D)指令長度固定、短,指令數少。
【C】75.CPU當中的旗標暫存器(Flag Register)內容是用來記錄 (A)指令運算的結果 (B)程式指令執行位址的指標 (C)指令執行後的狀態 (D)中斷向量位址。[112關務四等]
旗標暫存器的值可用來表示某種狀態(如:二數值的比較結果),進而影響程式執行流程。
【A】76.管線(Pipeline)計算中的數據風險(Data Hazar)可藉由指令碼排程(Code Scheduling)來避免管線停頓 (Pipeline Stall)的發生,其中指令碼排程是由下列那個系統程式負責? (A)編譯器(Compiler) (B)載入器(Loader) (C)作業系統(Operating System) (D)鏈接器(Linker)。[112關務四等]
每一種微處理器都有專屬的編譯器,負責將程式碼編譯成目的碼,再由連結器將目的碼連結成執行檔或二進位檔,交給微處理器執行。
【C】77.有關邏輯電路設計之敘述,下列何者錯誤? (A)欲解2n個碼時,解碼器之輸入至少要n個以上才能達成 (B)計算機中之記憶體為序向電路 (C)全加法器可以2個半加法器及1個NAND閘組合而成 (D)計算機中之加法器為組合電路。[112關務四等]
全加法器:2個半加法器及1個OR閘組成
【B】78.下列何種技術,在單一個晶片裡面內含有2個以上的CPU? (A)叢集電腦(Cluster computers) (B)多核心(Multi-Core) (C)超執行緒(Hyper-Threading) (D)複雜指令集(Complex Instruction Set
Computer, CISC)。[112鐵路員級]
多核心處理器:將多個獨立的處理器封裝在一起,每個獨立微處理器可平行處理程式中的執行緒(Threads),適合多工環境。
【B】79.下列處理器指令集中,何者是CISC(Complex Instruction Set
Computer)指令集?①Intel x86②RISC-V③ARM④Intel 8051⑤MIPS (A)②③④ (B)①④ (C)①③ (D)③④⑤。[112鐵路員級]
屬於複雜指令集的處理器有CDC 6600、System/360、VAX、PDP-11、Motorola 68000家族、x86、AMD Opteron等。
【D】80.在一個機器週期(machine cycle)中,下列那一個程式執行流程正確? (A)解碼→執行→擷取 (B)解碼→擷取→執行 (C)執行→擷取→解碼 (D)擷取→解碼→執行。[113地方四等資處]
機器週期:擷取→解碼→執行→儲存
【B】81.一個最簡單的半加器(half adder),至少需要幾個基本邏輯閘(如:AND、OR、NOT、XOR等)? (A)1個 (B)2個 (C)3個 (D)4個。[113地方四等資處]
一個最簡單的半加器,至少需要使用一個AND閘和一個XOR閘。
【B】82.一般而言,處理器利用下列那一個元件,記錄下一個要抓取的指令的記憶體位址? (A)指令暫存器(instruction register)
(B)程式計數器(program counter) (C)堆疊指位器(stack pointer) (D)指令解碼器(instruction decoder)。[113地方四等電子]
程式計數器:指出下一個要執行指令的記憶體位址。
【B】83.有一中央處理單元(CPU),擁有32bit位址匯流排(Address BUS),其理論的定址能力約為 (A)1GB (B)4GB (C)8GB
(D)16GB。[113身心五等]
2^32 = 2^2 × 2^30 bits = 4 GB
【C】84.CPU內的各種暫存器有其特定用途,下列那一個暫存器主要是用來存放下一個執行指令位址? (A)CX(Count Register)
(B)CS(Code Segment) (C)PC(Program Counter) (D)BP(Base Pointer)。[113身心五等]
程式計數器(Program Counter, PC):指出下一個要執行指令的記憶體位址。
【B】85.有關處理器執行指令之效能敘述,下列何者錯誤? (A)百萬指令每秒(million instructions
per second, MIPS)指的是某個處理器每秒可以處理多少特定程式之百萬個指令數 (B)百萬指令每秒(MIPS)可以被用來比較不同指令集的處理器之效能 (C)每指令時脈數(clock cycles per
instruction, CPI)指的是處理器執行特定程式所有指令的平均時脈數 (D)處理器執行某程式所需的時間為(執行該程式所需時脈數)乘以(時脈週期時間)。[113身心四等資處]
MIPS:每秒執行百萬個指令,衡量電腦效能常用的單位,沒有比較不同指令集的處理器之效能。
【B】86.CPU以循環的機器週期(machine cycle)執行程式中的每一行指令,機器週期的步驟順序為何? (A)解碼(decode)、執行(execute)、擷取(fetch) (B)擷取(fetch)、解碼(decode)、執行(execute) (C)解碼(decode)、擷取(fetch)、執行(execute) (D)執行(execute)、擷取(fetch)、解碼(decode)。[113身心四等資處]
機器週期的步驟順序:擷取→解碼→執行→儲存
【C】87.一個程式內含1000個指令,此程式在一個單核心5-stage管線化(pipeline)CPU中執行,每個stage耗時1個時脈週期(clock cycle),CPU的運作頻率為2GHz。若此程式有2%的指令會發生管線危障(hazard),且每次危障將導致1個時脈週期的管線暫停。此程式在CPU內的執行時間為 (A)220ns (B)1020ns
(C)512ns (D)5020ns。[113身心四等資處]
1.每個指令完成需要1個時脈週期,第1個指令完成需要5個時脈週期,故需要額外4個時脈週期。
基本時脈週期數=1,000+4=1,004個時脈週期
2.管線危障延遲=1,000×2%=20個時脈週期
3.總時脈週期數=1,004+20=1,024個時脈週期
4.每個時脈週期時間=1÷2GHz=0.5ns
5.總執行時間=0.5ns×1,024=512ns
【B】88.全加器(full adder)能將2個位元以及進位輸入(carry in)相加。其輸出有和(sum)及進位輸出(carry out)。假設所有使用到的邏輯閘之輸入至多有兩個,則全加器至少需要用到幾個基本邏輯閘(如:AND、OR、NOT、XOR)? (A)4個 (B)5個 (C)6個 (D)8個。[113身心四等資處]
全加器使用2個半加器與1個OR閘組成
半加器至少使用XOR閘、AND閘組成
全加器至少需要用到1個OR閘、2個XOR閘、2個AND閘
【B】89.關於半加器(half adder)與全加器(full adder)的敘述,下列何者正確? (A)半加器有2個輸入,全加器有2個輸入 (B)半加器有2個輸入,全加器有3個輸入 (C)半加器有1個輸出,全加器有2個輸出 (D)半加器有2個輸出,全加器有3個輸出。。[113身心四等資處]
半加器有兩個輸入a和b,兩個輸出分別為和與進位。
全加器的三個輸入訊號為兩個加數A、B和低位進位Cin。
【C】90.下列何者非中央處理元(Central Processing Unit)的組成元件? (A)算術邏輯單元(Arithmetic Logic Unit)
(B)控制單元(Control Unit) (C)資料計數器(Data Counter) (D)指令暫存器(Instruction Register)。[113初考資處]
CPU組成元件:CU+ALU+暫存器(Register)+快取記憶體(Cache Memory),主要原料是二氧化矽。
【B】91.作業系統讓行程(process)從就緒(ready)狀態進入執行(running)狀態,最可能是發生下列那一種狀況? (A)允許將程式碼放入記憶體 (B)允許使用中央處理器執行 (C)允許使用輸入或輸出裝置 (D)允許結束執行。[113初考資處]
從就緒狀態進入執行狀態時,表示行程已被分配到CPU並開始執行。
【B】92.當一個process包含多個threads時,下列資料何者不是多個thread共享?①register values②global variables③stack memory④heap memory (A)①② (B)①③ (C)③④ (D)②④。[113原民四等]
①register values:有獨立的暫存器數值
③stack memory:有獨立的堆疊
【B】93.一臺計算機有128MB(megabytes)的記憶體。儲存一個字需要4個位元組(Bytes),則記憶體中需要多少個位元(bit)來定址字元? (A)24 (B)25 (C)26 (D)27。[113普考資處]
記憶容量:128MB = 2^27Bytes
每個字組:4Bytes = 2^2Bytes
定址字組:2^27 ÷ 2^2 = 2^25
【C】94.快取記憶體(cache memory)對於電腦效能有極大的影響,關於快取記憶體在多核心(multi-core)電腦架構中的敘述,下列何者錯誤? (A)每一個核心皆具有獨立的L1快取記憶體 (B)多核心架構可以不配置共用快取記憶體 (C)不同的核心可透過各自的專用匯流排(bus)直接存取主記憶體(main memory)的資料至快取記憶體 (D)多核心共用L2或L3快取記憶體能提升系統可靠度及效能。[113普考資處]
(C)不同的核心,通常透過共享的匯流排來存取主記憶體。
【D】95.有一種記憶體功能,CPU先檢查它是否存有所需的資料。如果有,直接存取此資料;如果沒有,則存取主記憶體的資料。此記憶體稱為 (A)輔助記憶體(Auxiliary Memory) (B)堆疊(Stack) (C)基本輸入輸出系統(BIOS) (D)快取記憶體(Cache)。[113普考電子]
快取記憶體:材質為靜態隨機存取記憶體SRAM,解決CPU與主記憶體DRAM之間速度不平衡的現象,用來暫時儲存讀過的資料,下次讀取相同資料時,就直接從Cache讀取,不用再從輔助記憶體中讀取,增進處理效能。
【B】96.運用在許多消費性電子產品上的ARM處理器是一種精簡指令集架構(RISC)的處理器,下列何者與ARM同樣屬於精簡指令集架構CPU? (A)Intel Core i7
(B)MIPS (C)Motorola 68000 (D)AMD Athlon。[113關務四等]
MIPS(Microprocessor without Interlocked Pipeline
Stages),採取精簡指令集架構(ISA)。
【D】97.中央處理器使用一重複的機器週期(Machine Cycle)來執行程式中的指令,參與在擷取(Fetch)階段中的暫存器,下列何者正確? (A)算數暫存器(Arithmetic Register)與資料暫存器(Data Register) (B)算數暫存器(Arithmetic Register)與程式計數暫存器(Program Counter) (C)資料暫存器(Data Register)與指令暫存器(Instruction Register)
(D)指令暫存器(Instruction Register)與程式計數暫存器(Program Counter)。[113關務四等]
指令暫存器:存放記憶體中載入的運算碼。
程式計數器:指出下一個要執行指令的記憶體位址。
【A】98.與直接映射式快取記憶體(Direct-mapped cache)相比,全關聯式快取記憶體(Fully-associative
cache)主要可以降低下列何種快取記憶體失誤(cache miss)? (A)衝突失誤(conflict miss) (B)容量失誤(capacity miss) (C)強迫失誤(compulsory miss) (D)寫入失誤(write miss)。[113關務四等]
衝突性失誤(conflict miss):因取代策略造成區塊被取代,並再度對此區塊進行存取時造成的失誤,增加快記憶體大小可改善,使用fully associative可避免所有conflict miss。
【B】99.I/O裝置的控制一般而言會使用到4種暫存器(registers),不包括下列何者? (A)資料輸入暫存器(data-in register) (B)流程暫存器(flow register) (C)狀態暫存器(status register) (D)控制暫存器(control register)。[113關務四等]
I/O裝置的控制會使用到4種暫存器:
命令暫存器(command register):用於將命令發送給I/O裝置,例如讀取或寫入資料,清除中斷。
狀態暫存器(status register):用於顯示I/O裝置的當前狀態,例如是否就緒、是否發生錯誤。
資料輸入暫存器(data-in register):用於暫存從CPU發送到I/O裝置或從I/O裝置接收到的資料。
控制暫存器(control register):用於控制I/O裝置的操作,例如啟動或停止資料傳輸、選擇工作模式。
【B】100.有關指令集架構(instruction set architecture, ISA)的敘述,下列何者錯誤? (A)指令集架構為硬體與低階軟體(系統軟體)之間的抽象介面 (B)不同類型或廠牌的處理器,如:Intel與ARM處理器,皆使用相同的指令集架構 (C)指令集架構的內容包括:指令格式、暫存器、記憶體存取、輸出與輸入等 (D)應用二進制介面(application binary
interface, ABI)定義不同電腦間二進制可攜性的標準。[109地方四等資處]
Intel使用複雜指令集CISC。ARM使用精簡指令集RISC。
【B】101.有關處理器虛擬化的敘述,下列何者正確? (A)處理器虛擬化所造成的額外負擔(overhead)與工作負載所執行的指令類型無關,無論是以運算為主或是I/O密集都相同 (B)當作業系統呼叫(system call)使用的頻率較少時,處理器虛擬化所造成的額外負擔一般也較少 (C)具頻繁輸入輸出的工作,因為需要等待裝置處理資料,其處理器虛擬化的額外負擔非常高 (D)以運算為主(processor-bound)的程式執行時,處理器虛擬化的額外負擔非常高。[109地方四等資處]
虛擬化是一種資源管理技術,將電腦的各種實體資源(CPU、記憶體、磁碟空間、網路適配器等),予以抽象、轉換後呈現出來,並可供分割、組合為一個或多個電腦組態環境,打破實體結構間的不可切割的障礙,使用者可以比原本的組態更好的方式來應用這些電腦硬體資源。
【D】102.在中央處理器(CPU)的指令週期(instruction cycle)中,下列那一項操作可以不是必需的? (A)執行(execution) (B)解碼(decode) (C)指令擷取(instruction fetch) (D)寫回記憶體(write back)。[109身心四等]
CPU的指令週期依序:擷取、解碼、執行、儲存。前兩者合稱擷取週期(Fetch cycle),由CU負責;後兩者合稱執行週期(Execute cycle),由ALU負責。
【B】103.常見嵌入式處理器,如ARM與MIPS,皆使用記憶體映射(memory-mapped I/O)方式與外部的輸入/輸出裝置溝通。下列何者為此類型處理器對輸入/輸出裝置下命令所使用的指令? (A)算術與邏輯運算指令 (B)記憶體存取指令 (C)控制指令 (D)輸入/輸出指令。[109普考資處]
記憶體對映I/O使用相同的位址匯流排來定址記憶體和輸入輸出裝置,前提是I/O裝置上的裝置記憶體和暫存器都已經被對映到記憶體空間的某個位址。當CPU存取某個位址時,可能是存取某部分物理記憶體,也可能是存取I/O裝置上的記憶體。(wiki)
【C】104.多處理器(multiprocessor)架構可大致分為兩個類別:共享實體記憶體位址空間與各自擁有實體記憶體位址空間。針對多處理器架構,下列敘述何者錯誤? (A)共享實體記憶體位址空間的多處理器是利用快取一致的共享記憶體(cache coherent shared
memory),來達到處理器之間的通訊(communication) (B)各自擁有實體記憶體位址空間的多處理器間,是利用訊息傳遞(message passing)來達到處理器之間的通訊 (C)就硬體設計而言,共享實體記憶體位址空間的多處理器,相較於各自擁有實體記憶體位址空間的多處理器簡單 (D)就程式設計而言,移植一個循序(sequential)程式至藉由訊息傳遞的多處理器上平行化執行是比較困難的,因為任何一個處理器之間的通訊都需要在程式中明確敘述,否則程式無法正確執行。[109普考資處]
(C)共享實體記憶體位址空間的多處理器,設計比較困難。
【C】105.隨著電腦科技的演進處理器可以扮演的角色日趨多元,下列那一個類型的處理器,較為適宜用於螢幕繪圖(graphics rendering)與高效能計算? (A)CPU(central
processing unit) (B)DSP(digital signal processor) (C)GPU(graphics processing
unit) (D)VGA(video graphics array)。[109普考資處]
圖形處理器(GPU):又稱顯示核心、顯示卡、視覺處理器、顯示晶片或繪圖晶片,是一種專門在個人電腦、工作站、遊戲機和行動裝置(平板電腦、智慧型手機)上執行繪圖運算工作的微處理器。(wiki)
【D】106.下列何者不適用於敘述圖形處理器(graphics processing unit, GPU)的特性? (A)SIMD(Single
Instruction stream, Multiple Data streams) (B)MIMD(Multiple Instruction
streams, Multiple Data streams) (C)多緒處理器 (D)低記憶體延遲。[109普考資處]
DDR搭配CPU的要求是低記憶體延遲。GDDR搭配GPU的延遲比DDR高。
【A】107.假設我們有一個平行計算程式,其中有65%的工作屬於理想平行計算(Parallel Computation),35%的工作屬於循序計算(Sequential Computation),如果我們現在使用8處理核心(Core)的處理器(Processing Unit),相對於使用只有單一處理核心的處理器,假設每個處理核心都具有相同的運算能力,此工作最快約能加速多少倍? (A)2.32 (B)3.35 (C)4.23
(D)5.15。[109普考資處]
阿爾達姆法則 S = 1 / (1 - a + a / n)
S:總系統提升的效率為原來的S倍。
a:部分系統影響總系統效率的比率。
n:部分系統提升的效率是原來的n倍。
S=1 / (1 - 65% + 65% / 8) = 2.32
【C】108.在平行計算的模式中,有所謂的數據平行性(data parallelism)和工作平行性(task parallelism)。下列那一種平行計算行為屬於工作平行性? (A)計算向量的內積 (B)計算3D繪圖的光線追蹤(ray-tracing) (C)同步影音解碼 (D)計算一個整數陣列元素的總和。[109普考資處]
數據平行性:將大量資料進行分解,並交給多個處理器進行處理。
工作平行性:在同一資料集中,將任務分解成多個子任務,分別交付不同的處理器執行。
【C】109.下列有關處理器運作之時脈週期(clock period)敘述,何者錯誤? (A)時脈週期之長度可用時脈週期的時間或時脈速度(clock rate)來表示 (B)時脈週期的時間與時脈速度,兩者互為倒數 (C)處理器的時脈週期時間越大,代表處理器的處理速度越快 (D)時脈速度通常使用赫茲(hertz)為單位來表示。[109關務四等]
(C)時脈週期為時脈頻率的倒數,時間越大,代表處理速度越慢。
【B】110.下列有關處理器之指令流與資料流分類的敘述,何者錯誤? (A)SIMD(Single
Instruction stream, Multiple Data streams)處理器可在一個時脈週期中,利用單一指令來處理多筆不同的資料,因此相對於SISD(Single Instruction stream,
Single Data stream)處理器,在處理結構性資料時較有效率 (B)SIMD(Single Instruction stream,
Multiple Data streams)處理器可充分利用資料層級平行性(data-level parallelism),因此當程式中有很多case或是switch敘述時,此類型處理器表現最好 (C)單一程式多資料(Single Program Multiple
Data, SPMD)的程式結構為MIMD(Multiple Instruction streams, Multiple Data
streams)處理器上編程的一種方法 (D)MIMD(Multiple Instruction streams, Multiple Data
streams)處理器可在一個時脈週期中處理屬於多個程式之多筆資料,多核心處理器(如Intel Core i7系列處理器)即為此類別的處理器。[109關務四等]
單指令流多資料流(SIMD):採用一個控制器來控制多個處理器,使用同一個指令對不同資料及相對的處理器做個別操作,實現並列性的技術。
【C】111.硬體多緒處理(hardware multithreading)允許多個執行緒(threads)有效率地共用一個處理器。要允許上述的共用,處理器必須要支援可以迅速切換執行緒的能力。下列何者為處理器在進行執行緒切換時,所需要保存的個別執行緒的狀態? (A)快取記憶體的資料 (B)記憶體的資料 (C)暫存器與程式計數器(program counter)的資料 (D)算數運算器的資料。[109關務四等]
處理器在進行執行緒切換時,需要保存暫存器與程式計數器的資料。
【D】112.有關轉譯側查緩衝器(translation-lookaside buffer, TLB)的定義,下列何者正確? (A)用來檢驗欲存取的資料是否快取命中(cache hit)的硬體機制 (B)用來檢驗是否發生分頁錯失(page fault)的硬體機制 (C)當快取命中(cache hit)發生時,用來記錄資料的緩衝器 (D)處理器中用來記錄最近用過的一些位址轉換資料的特殊緩衝器。[109關務四等]
轉譯側查緩衝器:具有固定數目的空間槽,用於存放將虛擬位址對映至實體位址的分頁表條目。快取命中:可由快取記憶體滿足對記憶體讀取資料的請求,不需用到主記憶體,與TLB無關。
【B】113.有關共享記憶體多處理器(shared memory multiprocessor)的敘述,下列何者錯誤? (A)提供單一實體記憶體位置空間(address space)給多處理器使用 (B)於多處理器上的所有程序(process)必須共享同一虛擬記憶體位置空間(address space) (C)若任一處理器存取任一記憶體中的一個字組(word),所花費的時間皆相同,則稱之為一致的記憶體存取(uniform memory access,
UMA) (D)若不同處理器存取記憶體中的同一個字組(word),所花費的時間可能不同,則稱之為非一致的記憶體存取(nonuniform memory
access, NUMA)。[110地方四等資處]
(B)多處理器都連接到同一個共享的主記憶體上,並由單一作業系統來控制。
【C】114.管道式處理器(pipelined processor)在執行一道算術指令時,若該計算發生滿溢的狀況,最早可在那個階段被偵測? (A)擷取(fetch) (B)解碼(decode) (C)執行(execute) (D)寫回(write back)。[110地方四等資處]
滿溢在執行和寫回階段才會被偵測到。
【C】115.某處理器具有32-bit記憶位址,該處理器上具有一32K Byte大小的4-way set associative
cache,每個cache block為16Byte。該cache的address tag寬度為何? (A)17 (B)18 (C)19 (D)20。[110地方四等電子]
32=25,32=25,4=22,16=24,1Byte=23bits,合計219
【A】116.使用多個處理器,在同一時間可以在各自處理器上運行程序這種作法稱為 (A)Multiprocessing
(B)Multiprogramming (C)Multitasking (D)Multithreading。[110地方四等電子]
(B)多元程式:CPU會在目前執行的程式因等待I/O而閒置時,轉移服務另一個程式,提高CPU的使用效率。
(C)多工作業:電腦可同時執行多個程式。
(D)多執行緒:在閒置或等待時,透過在不同執行緒間快速切換,提升效率。
【A】117.針對共享記憶體多處理器(shared memory multiprocessor, SMP)敘述,下列何者錯誤? (A)所有處理器共用一個虛擬位址空間 (B)所有處理器可以存取任何記憶體位置 (C)某一處理器對某些記憶體存取可能會遠快於對其他記憶體存取之時間 (D)所有處理器在平行運作時,可透過共享的記憶體傳遞資料。[110身心四等]
SMP擁有超過多個處理器,所有處理器都連接到同一個共享的主記憶體上,並由單一作業系統來控制。
【B】118.在單一處理器架構的循序處理模式中,有一種技術讓多個指令的執行可以重疊,使得處理器執行程式的硬體效率提高、執行時間縮短,此為何種技術? (A)虛擬機器(Virtual
Machine) (B)管道化處理(Pipelining) (C)虛擬記憶體(Virtual Memory) (D)快取機制(Caching)。[110身心四等]
管線運算(Pipeline):將一個指令循環拆成若干個不同的步驟,每個步驟設計一個特定元件專門負責固定的工作,並將這些元件排成一條一貫作業生產線(或管線),當某個元件完工時,就將半成品交給下一個元件。提升CPU工作效率。
【B】119.在多重處理器的排程(Multiple-Processor Scheduling)問題中,有時候必須將某程序安排在同一個處理器上來執行以提升其執行效率,稱之為處理器親和性(Processor Affinity),通常是基於下列那一項因素的考量? (A)檔案儲存裝置(File Storage)
(B)快取記憶體(Cache Memory) (C)處理器暫存器(Processor Register) (D)關聯式記憶體(Associative Memory)。[110身心四等]
對稱式多重處理系統避免排程從一個處理器轉移到另一個處理器,而試著讓一個排程在同一處理器上執行,這就是處理器親和性,表示排程對並行執行的處理器有親和性。
【C】120.具備大量資料層級平行性(data-level parallelism)的程式,使用下列那種處理器架構進行運算時,會有最大的效能提升? (A)純量架構(scalar
architecture) (B)超純量架構(superscalar architecture) (C)向量架構(vector architecture) (D)動態管道排程(dynamic pipeline scheduling)。[110身心四等]
資料平行(Data
parallelism):是多處理器的平行運算模式,將資料均分到不同的平行運算節點中。
向量處理器:又稱數組處理器,是直接操作一維數組(向量)指令集的中央處理器,可以在特定工作環境中,會有最大的效能提升。
【A】121.現有一個循序程式(sequential program)於單一處理器執行時,需時120秒,其中,有20秒的執行是無法平行化的(無法從多處理器平行執行時得到好處)。若將此程式平行化後,於10個處理器上執行時,最高可以得到多少倍的加速(speedup)? (A)4 (B)6 (C)7.5 (D)10。[110普考資處]
平行化後時間=不可平行化時間+可平行化時間÷核心數=20+(120-20)÷10=30秒
最高加倍=120÷30=4倍
【D】122.對於計算機設計而言,使用多處理器系統(multiprocessor system)相對於單處理器的主要優點中,不包含下列何者? (A)執行程式的吞吐量的提升(increased throughput) (B)相對於同樣工作處理能力的多台單處理器較具經濟效益(economy of scale) (C)可靠度的提升(increased reliability) (D)時脈的提升(increased clock rate)。[110普考資處]
多處理器系統的優點:1.增加吞吐量,2.具經濟效益,3.增加可靠性。
【C】123.設以管道化(Pipelining)機制改善中央處理單元(Central Processing Unit, CPU)效能時,且管道中包含五個步驟:指令執行(Instruction Execute)、指令解碼(Instruction Decode)、記憶體存取(Memory Access)、結果寫回(Result Write Back)與指令擷取(Instruction Fetch)。通常處理器以何種步驟的順序完成一道指令的執行? (A)指令執行、記憶體存取、結果寫回、指令擷取與指令解碼 (B)指令解碼、記憶體存取、指令執行、結果寫回與指令擷取 (C)指令擷取、指令解碼、指令執行、記憶體存取與結果寫回 (D)結果寫回、記憶體存取、指令擷取、指令解碼與指令執行。[110普考資處]
【D】124.對於處理器中暫存器(Register)的敘述,下列何者錯誤? (A)常數暫存器未必需要用到記憶體元件 (B)索引(Index)暫存器是位址暫存器的一種 (C)通用目的暫存器(General Purpose Registers)可以儲存資料或位址 (D)向量暫存器用來儲存由向量處理器執行MIMD指令所得到的資料。[110普考資處]
向量暫存器用來儲存由向量處理器執行SIMD指令所得到的資料。
【B】125.下列何種應用類別以圖形處理器(graphics processing unit, GPU)運算會比中央處理器(central processing unit, CPU)執行時,更有效率? (A)有大量輸入輸出(input/outpour operations)的資料庫應用 (B)每一筆資料都可以獨立處理的串流(stream)資料運算 (C)程式編譯(compilation) (D)具備許多分支控制指令的程式。[110關務四等]
GPU的核心架構設計採用單元串流處理(Stream Processors),內建數量眾多的處理單元平行運算,在運算3D圖形時,更突顯優異效率。
【B】126.某循序程式的執行時間中有90%是可被平行化(parallelizable)的部分。若欲以多核心(multi-core)處理器取得2倍的加速(speedup),至少需要幾個核心? (A)2 (B)3 (C)4 (D)5。[110鐵路員級]
90÷X=Y
100÷(Y+10)=2
Y=40,X=2.25,至少需要3個核心
【A】127.處理器執行時,除了分支與跳躍外,能改變正常指令執行路徑的事件為例外(exceptions)和插斷(interrupts),下列何者並非由處理器內部所產生的插斷情況? (A)I/O裝置發出請求 (B)使用者程式呼叫作業系統 (C)算術滿溢 (D)使用未定義的指令。[111地方四等資處]
i(A)I/O裝置發出請求屬於外部插斷。
【A】128.若一處理器的時脈速度為200MHz,且CPI(指令平均時脈週期數)為4,則此處理器的MIPS為多少? (A)50 (B)200
(C)800 (D)80000。[111地方四等資處]
MIPS=200M÷4=50M
【D】129.使用阿姆達爾定律(Amdahl's Law)來考慮下列問題:一個應用程式中,有百分之四十的部分只能循序(serial)執行,另外百分之六十的部分可以完全平行(parallel)執行,如果透過增加核心的數量來達到應用程式的速度提升(speedup),若以單核心的環境做為比較的基準,此應用程式在多核心系統上速度提升的上限是多少? (A)1.4倍 (B)1.6倍 (C)1.7倍 (D)2.5倍。[111地方四等資處]
去除完全平行就是最高的上限
速度提升=1÷40%=2.5倍
【D】130.某一處理器的指令運算碼(operation code)長度為7個位元,該運算碼最多可解碼出幾種不同的指令? (A)7 (B)28 (C)64 (D)128。[111身心四等]
27 = 128
【C】131.某處理器為具有5個stages的管線式處理器,各管線階級(pipeline stage)分別為instruction fetch(IF),
instruction decode(ID), execution(EX), memory(MEM), write back(WB)。各stage所需的運算時間分別如下:
IF: 2.5ns
ID: 1.0ns
EX: 1.5ns
MEM: 4ns
WB: 3.0ns
則該處理器可執行的最快時脈頻率為何? (A)1GHz (B)0.5GHz (C)0.25GHz
(D)0.10GHz。[111身心四等]
最長需時4ns,最快時脈頻率=1÷4ns=0.25GHz
【D】132.對下列不同的微處理器架構,那一項不是採用平行運算的技術? (A)動態管道排程(dynamic pipeline
scheduling) (B)SIMD(Single Instruction stream, Multiple Data streams
architecture)架構 (C)向量架構(vector architecture) (D)純量架構(scalar architecture)。[111普考資處]
(D)純量架構採用並行運算的技術。
【D】133.高階處理器如Intel Core i7系列處理器,利用較深的管道化設計(pipelining)與積極的多重派發以提升執行效能。下列何者並非造成管道停滯進而影響此類型處理器效能的主因? (A)需要長執行時間的指令 (B)難以預測的分支 (C)過多的快取錯失(cache misses) (D)過大的主記憶體容量。[111關務四等]
(A)指令需要長執行時間,會影響處理器效能。
(B)使用分支預測可提高效能,若分支難以預測,會影響處理器效能。
(C)當快取錯失時,需到主記憶體擷取資料,會影響處理器效能。
【C】134.關於雙核心CPU的敘述,下列何者正確? (A)雙核心CPU就是32位元×2,也就是所謂的64位元CPU (B)雙核心CPU的時脈計算方式,就是單核心的時脈×2 (C)雙核心CPU是利用平行運算的概念來提高效能 (D)雙核心CPU就是指加入了Hyper-Threading技術的CPU。[111關務四等]
多核心處理器與平行處理(Parallel Processing):將多個獨立的處理器封裝在一起,每個獨立微處理器可平行處理程式中的執行緒(Threads),提升效能,適合多工環境。
【B】135.各項處理器設計策略,下列何者不是RISC(Reduced Instruction Set
Computer)的設計方針? (A)透過編譯器的指令排程(instruction scheduling)以提升管線式(pipeline)架構的運算效能 (B)讓每個算術運算指令皆可讀寫記憶體運算元,以提升運算效能並降低指令數量 (C)算術運算指令僅可使用暫存器運算元,並透過編譯器的暫存器配置(register allocation)提升運算效率 (D)讓每道指令皆有相同的指令長度,以便於設計超純量(superscalar)處理器架構。[111鐵路員級]
精簡指令集(RISC)的特點:指令長度固定,指令格式種類少,定址方式種類少,大多數指令能在一個時鐘週期內完成,易於設計超純量(superscalar)與管線技術(pipeline),由於暫存器數量多,可以增加平行處理能力。
【A】136.某低成本嵌入式處理器僅具有加法器與移位器(shifter),而不具備乘法器。乘法運算須由加、減與移位(<<)運算進行。欲計算某變數A乘以十六進位數字6C,下列計算方式何者正確?
(A)(A<<6)+(A<<5)-(A<<2)
(B)(A<<6)+(A<<5)+(A<<4) (C)(A<<7)-(A<<<5)
(D)(A<<5)+(A<<2)-A。[112地方四等電子]
A<<1=2,A<<2=4,A<<3=8,A<<4=16,A<<5=32,A<<6=64,A<<7=128
(A)(A<<6)+(A<<5)-(A<<2)=64+32-4=92
(B)(A<<6)+(A<<5)+(A<<4)=64+32+16=112
(C)(A<<7)-(A<<5)=128-32=96
(D)(A<<5)+(A<<2)-A=32+4-2=34
16進位6C為10進位108,16進位5C為10進位92,答案待解
【D】137.假設有一個虛構的處理器擁有8個暫存器(R),定址空間1Mwords(M),以及提供32個不同指令如(add,
sub,...),指令格式為:<Instructions><M><R>,則此種指令所需之最小位元(bit)數為何? (A)16 (B)32 (C)24 (D)28。[112地方四等電子]
8個暫存器:2^3
定址空間1M:2^20
提供32個指令:2^5
指令所需之最小位元數=3+20+5=28bits
【D】138.下列何者能提供較高的I/O傳輸速率? (A)中斷驅動I/O(interrupt-driven
I/O) (B)記憶體映射I/O(memory mapping I/O) (C)程式控制I/O(program-controlled
I/O) (D)直接記憶體存取I/O(direct memory access I/O)。[112關務四等]
DMA允許周邊與記憶體兩者直接傳送,資料傳輸速率快,一般用在大量資料傳送,但需額外電路、成本高,程式規劃複雜。
【B】139.某循序程式的執行時間中,有80%的部分可被改寫為四個相同程式的thread平行執行,另外20%的部分僅能循序執行。若將該程式以multi-thread的方式改寫並於四核心處理器上執行,所能獲得的加速(speedup)最大上限為何? (A)2.0 (B)2.5 (C)3.0
(D)3.5。[112鐵路員級]
改寫後的執行時間 = 80% ÷ 4 + 20% = 40%
加速 = 1 ÷ 40% = 2.5
【D】140.有關平行處理與虛擬化技術的敘述,下列何者正確? (A)虛擬化技術是利用平行處理的原理,讓每一個虛擬機器同時可以利用硬體平台上所有的資源進行平行運算 (B)每一個虛擬機器皆各自擁有一個獨立的實體位址空間 (C)虛擬化技術造成微處理器額外負擔,因此以運算為主(processor-bound)的程式執行時,會需要負擔大量的虛擬化成本 (D)一個虛擬機器中,可利用平行處理技術,讓一個平行程式在多核心處理器上運行,縮短程式執行時間。[113地方四等資處]
(A)平台虛擬化,將作業系統和硬體平台資源分割,讓所有軟體都能在虛擬機器中執行。
(B)虛擬軟體可以模擬實體硬體的功能,在單個實體機器上,同時執行多個虛擬機器。
(C)虛擬化的負擔與工作負載的指令類型有關。
【C】141.為提高運算效能,超純量(superscalar)處理器通常採用亂序(out-of-order)及預測式執行(speculative execution)的方式執行指令。然而,當指令發生例外(exception)狀況或遇到中斷(interrupt)時,可能必須刪除某些已預先執行指令的結果,使處理器的狀態倒回某循序指令結束時的狀態,做到precise interrupt。下列超純量處理器中的微架構機制,何者是用於實現precise interrupt的必要機制? (A)instruction
dispatcher (B)reservation window (C)reorder buffer (D)branch target buffer。[113地方四等電子]
在Tomasulo算法中,重排序緩衝區(reorder buffer, ROB)可以使指令在亂序執行,之後按照原有順序提交。
【B】142.當微處理器進行數值運算時須要檢查,以確認結果的正確性,下列何者是除法運算時須要檢查的項目? (A)數值精確度 (B)數值滿溢、除以零 (C)指令長度 (D)資料表示法。[113身心四等資處]
數值滿溢,在編譯時,會發生錯誤。
除以零,該數值無意義。
【C】143.關於VLIW(Very Long Instruction Word)處理器的敘述,下列何者錯誤? (A)其設計策略是要開發指令階層平行度(instruction level
parallelism),每個時脈週期可同時執行多個運算(operation) (B)可透過software pipelining編譯技術增加迴圈(loop)程式的執行效率 (C)具備硬體機制偵測運算間的資料相依性,並於程式執行時自動發掘可平行執行的運算 (D)可透過trace scheduling編譯器指令排程技術提高程式執行效率。[113身心四等電子]
VLIW處理器需要依賴純軟體的方式,以發掘指令階層平行性進而提升程式效能。
【A】144.某些電腦會有TLB(Translation Look-aside Buffer)硬體,下列何者為TLB的主要功能? (A)將虛擬記憶體位址的頁碼(page number)加速轉換成實體位址的頁框碼 (B)減少發生快取記憶體失誤(cache miss)的機率,提高電腦的性能 (C)支援直接記憶體存取(Direct Memory Access),減少CPU等待I/O裝置的時間 (D)當作快取記憶體(cache)和主記憶體之間的緩衝器(buffer),減少CPU等待主記憶體的時間。[113普考電子]
TLB用於虛擬記憶體到實體記憶體的對應,加速轉換時間。
【D】145.下列何者不是共享記憶體多處理器(shared memory multiprocessor, SMP)在平行運作時,用來同步(synchronization)共享資料的存取,以確保程式正確執行的機制? (A)共享變數的鎖(lock) (B)不可切分的交換(atomic swap) (C)載入聯結(load linked)/條件儲存(store conditional)機制 (D)程序切換(context switch)。[113關務四等]
程序切換(上下文交換):CPU在執行時,只能呼叫一個行程,如果要切換另一個行程時,須先行儲存目前行程的相關資訊,才將新行程的相關資訊載入CPU中。
【B】146.設計4-to-1多工器(Multiplexer)時,需要幾個位元的選擇輸入訊號? (A)1 (B)2 (C)3 (D)4。[110地方四等資處]
4-to-1有4種情況,4 = 22,需要2個位元
【C】147.雙向移位器(Bi-Directional Shifter)的設計中,除了D型正反器(D flip-flops)外,使用下列何種邏輯元件最為適宜? (A)編碼器 (B)解碼器 (C)多工器 (D)計數器。[110地方四等資處]
在雙向移位器中,多工器根據控制信號選擇向左或向右移位進行數據傳輸。
【C】148.下列數位電路圖中,何者為循序電路(sequential
circuit)? [110地方四等電子]

循序電路:根據過去和現在的輸入值來改變輸出值,將輸出值存於正反器(flip-flop)中,然後將輸出值傳送到下一時序作為另一個輸入值。
【D】149.某一多工器(multiplexer)有4條選擇控制線,對此多工器敘述,下列何者正確? (A)該多工器有1個輸入通道、(至多)4個輸出通道 (B)該多工器有1個輸入通道、(至多)16個輸出通道 (C)該多工器有(至多)4個輸入通道、1個輸出通道 (D)該多工器有(至多)16個輸入通道、1個輸出通道。[110地方四等電子]
4條選擇控制線,最多有16(2的4次方)個輸入通道,1個輸出通道。
【C】150.關於邏輯電路中所使用的4對1多工器(4-to-1 multiplexer),下列敘述何者錯誤? (A)有4條資料輸入線 (B)有1條資料輸出線 (C)有1條選擇線 (D)屬於組合邏輯電路的一種。[110身心四等]
有2條選擇線

循序邏輯電路:1.會依賴同步訊號來更新內部變數的值。2.同步訊號通常為系統的時脈(clock)。3.Latch、Flip Flop皆屬之。
【B】152.某個數位電路設計使用到一個解多工器(demultiplexer),該解多工器的選擇控制線共有6條,下列敘述何者正確? (A)該解多工器有1個輸入通道、(至多)6個輸出通道 (B)該解多工器有1個輸入通道、(至多)64個輸出通道 (C)該解多工器有(至多)6個輸入通道、1個輸出通道 (D)該解多工器有(至多)64個輸入通道、1個輸出通道。[110鐵路員級]
(B)6條選擇控制線,1個輸入通道,2 ^ 6 = 64個輸出通道。
【B】153.如圖所示之組合邏輯電路,其功能相當於 (A)XNOR閘 (B)XOR閘 (C)NAND閘 (D)NOR閘。[111地方四等資處]
【C】154.下列何者應用電路的設計,一定得使用到循序電路? (A)BCD至七段解碼器的設計 (B)全加器 (C)紅綠燈號控制器 (D)浮點數乘法器。[111普考電子]
循序電路:由本次加上次的輸入來決定輸出,與時序相關,具記憶功能。
(A)(B)(D)為組合電路。
【D】155.下列何者不是組合電路(Combinational circuit)? (A)半加器(Half adder) (B)多工器(Multiplexor) (C)解碼器(Decoder) (D)正反器(Flip flop)。[111普考電子]
組合電路:完全由輸入組合來決定輸出,如:比較器、數據多工器、編(解)碼器、全(半)加器、全(半)減器。

【C】157.由6個正反器(flip-flops)所組成的二進制同步(synchronous)計數器,可由0計數到最大值為多少? (A)31 (B)32 (C)63 (D)64。[112地方四等資處]
2^6 - 1 = 63
【D】158.下列電路元件中,何者是具有記憶功能的儲存元件?
 。[112地方四等電子]
。[112地方四等電子](A)XNOR反互斥或閘,(B)NAND反及閘,(C)OR或閘,(D)電路元件。
【A】159.以下的邏輯線路圖

有兩個1-bit的輸入a及b,產生1-bit的輸出。請問這個邏輯線路跟那一個運算結果是一樣的? (A)NOT(a OR b) (B)NOT(a
AND b) (C)a XOR b (D)NOT(a XOR b)。[112國安五等]
A'•B' → A' AND B' → (A+B)' → NOT(A OR B)

C = A NAND D = 0 NAND 0 = 1
D = B NAND C = 1 NAND 1 = 0
【D】161.關於循序邏輯(Sequential
logic)與組合邏輯(Combinational logic)的比較,下列何者正確? (A)組合邏輯具有回授路徑(feedback path) (B)組合邏輯的輸出與輸入及目前狀態(present state)有關 (C)組合邏輯內部包含有記憶元件 (D)漣波計數器(ripple counter)可歸類於循序邏輯。[112關務四等]
(A)組合邏輯無回授路徑。
(B)組合邏輯僅與目前輸入變量的取值有關。
(C)組合邏輯內部無記憶元件。
(D)漣波計數器又稱為異步計數器(Asynchronous
Counter),是由一連串的JK正反器所構成,可歸類於循序邏輯。
【B】162.下圖的循序電路包含二個D flip flops A與B及一個輸入訊號X。

其行為以狀態轉換圖(state transition
diagram)表示,何者正確?(狀態以"AB"表示之。例如:狀態01代表A=0,B=1 )
 。[112鐵路員級]
。[112鐵路員級]【D】163.假設你只有1-to-4解多工器(demultiplexer)的元件可以使用,則總共需要幾個1-to-4解多工器元件,才能組合成一個1-to-64解多工器? (A)12 (B)16 (C)20 (D)21。[113地方四等電子]
【B】164.考慮如圖所示之邏輯電路,若最終輸出X為0,則下列輸入何者錯誤? (A)A=0, B=0, C=1, D=0 (B)A=0, B=1, C=0, D=0 (C)A=0, B=1, C=1, D=0
(D)A=0, B=1, C=1, D=1。[113普考資處]
 |
A |
B |
A
and B = E |
C |
D |
C
or D = F |
E
nor F |
|
0 |
0 |
0 |
1 |
0 |
1 |
0 |
|
|
0 |
1 |
0 |
0 |
0 |
0 |
1 |
|
|
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
|
0 |
1 |
0 |
1 |
1 |
1 |
0 |
【B】165.某個編碼器(encoder)共有45條輸入線(輸入值只有1個位元是1,其餘44位元是0),則該編碼器至少要有多少條輸出線? (A)4 (B)6 (C)8 (D)12。[113普考電子]
decoder用來將binary code變成one-hot code,有1對1關係
2^5≦45≦2^6
【C】166.如圖所示之邏輯電路,若起始值Q3Q2Q1Q0=0000,則經過幾次的時脈觸發(clock triggerings)後會回到Q3Q2Q1Q0=0000? (A)2 (B)4 (C)8 (D)16。[113關務四等]
 |
狀態 |
Q0 |
Q1 |
Q2 |
Q3 |
Q3Q2Q1Q0 |
|
0 |
0 |
0 |
0 |
0 |
0000 = 0 |
|
|
1 |
1 |
0 |
0 |
0 |
|
|
|
2 |
1 |
1 |
0 |
0 |
|
|
|
3 |
1 |
1 |
1 |
0 |
|
|
|
4 |
1 |
1 |
1 |
1 |
|
|
|
5 |
0 |
1 |
1 |
1 |
|
|
|
6 |
0 |
0 |
1 |
1 |
|
|
|
7 |
0 |
0 |
0 |
1 |
1000 = 8 |

沒有留言:
張貼留言
注意:只有此網誌的成員可以留言。